
“We” is a great example of why use of pronouns can signal potential deception. It is a weasel word that sounds as specific as “I” yet almost any specific attribution can be plausibly denied because the referents usually remain anonymous. The deceptive power lies in the automatic sense-making that humans do when wereceive a communication.
Use of “We”is a classic impression management strategy that is popular with deceivers because it communicates self-aggrandising virtues such as strength, support, authority and alliance. We thinks we are royalty! (For examples see my earlier blogpost on deceptive ‘we’ featuring an analysis of David Cameron)
In the context of Academic and Research Integrity, “we” signals authorship, responsibility and credit and should obviously be clearly specified . So, it is ironic that my new example of the deceptive power of “we” comes from an academic integrity forum (the JISC Plagiariasm Mailing list).
Take a look at the email below. Anything suspicious?!
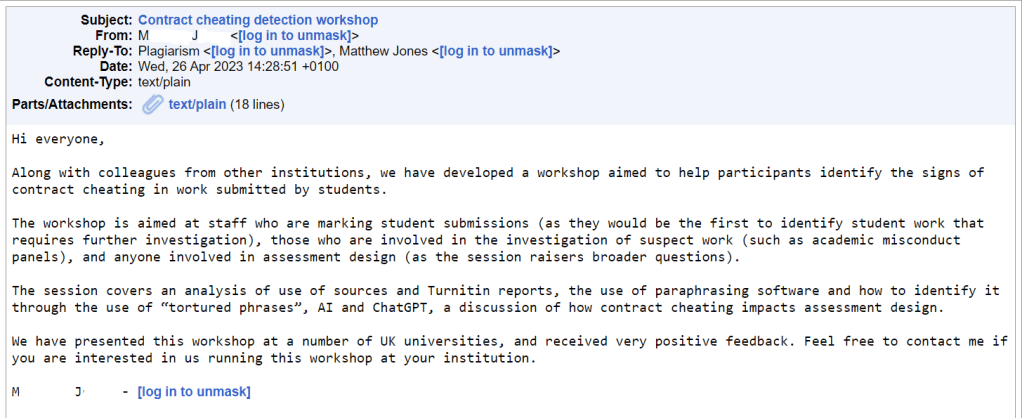
It comes from ‘M J’ (full name hidden) who is advertising academic consultancy services. He claims to be working with “colleagues from other institutions” but these remain anonymous behind the veil of “we”. At the end of the email he again refers to this mysterious but very successful “we” (self-aggrandising) but again refrains from detailing ‘who is we’. The lack of proofreading also suggests potential spam. In the context of an academic integrity forum this is odd linguistic behaviour so I delve deeper.
It turns out, ‘M J’ is offering contract cheating detection services targeted at assessment markers – something I published about recently (see my paper Decision Support for Marker Detection of Contract Cheating In fact, the workshop looks very similar to one I have been offering with Dr Lorna Waddington from Leeds University
In fact, his name looks familiar…As you know, I led a project in 2021 to create the most comprehensive contract cheating detection checklist in the UK to date. (See this post). I worked on that with Dr Waddington and 3 other academic integrity enthusiasts. I checked my list of collaborators on that project and sure enough there was a Matthew Jones. It is a common name but I was sure it was him!
Academic consultancy services are a grey area (see my typology of commercial academic writers )that requires full transparency if you are going to engage with it. Otherwise you become Chegg! Imagine if Chegg said “we are running Contract Cheating detection workshops for markers) – how credible would that be?!? (but see the new Cheggmate press release…). Advertising such services using at best obfuscating strategies – and on a plagiarism forum no less – does not inspire trust.
I will need to investigate the extent to which ‘M J’ has been promoting himself in this way…Stay tuned!
