
Alan Dershowitz, the Harvard Professor and reputed criminal defense lawyer whose list of prominent clients includes O.J Simpson, Harvey Weinstein, Donald Trump, and his close friend the late Jeffrey Epstein, had been accused by Virginia Roberts Giuffre of sexually abusing her as a teenager on multiple occasions whilst in the company of Epstein.

Dershowitz (second left) standing between Jeffrey Epstein and Steven Pinker at a Harvard dinner party in 2004 (Source: r/Epstein, 2020)
Dershowitz was irked (to say the least) that these accusations were made in a public court filing for a case that he was not a party to as this gave him no opportunity to defend himself yet left him open to media scrutiny

Excerpt from the statement submitted by Bradley J. Edwards and Paul G. Cassell, lawyers of Virginia Roberts Giuffre [Case No. 08-80736-Civ-Marra/Johnson] mentioning Alan Dershowitz. ‘Jane Doe #3’ is Virginia Roberts Giuffre.
Dershowitz fought back, filing a motion requesting to intervene in the case, on the basis that the accusations were false and irrelevant to the case at hand. (The Harvard Crimson, 7/1/2015). In that motion he made the statement analysed here.
Outliar™ ‘Linguistic Polygraph’ Methodology
Outliar™ Linguistic Polygraph is based on principles of deceptive communication drawn from Information Manipulation Theory (McCornack et al. 2014): that lies are built on truth and therefore deception most often produces texts that are a strategic mixture of truth and lies. Using this insight, the Outliar™ methodology utilizes the most sensitive linguistic deception cues (LDCs) drawn from the academic literature (see Hauch et al. 2015 for a good overview), as well as LDCs used on investigator training programmes, in order to identify and separate credible and suspicious content (see Popoola (2017) for a case study). Disclaimer: Outliar™ is not a lie detector. It is an investigative linguistic tool that highlights credible text segments and identifies suspicious text segments as ‘points of interest’ deserving further investigation i.e. loci of potential deception.
Alan Dershowitz statement: analysis
Credible segment
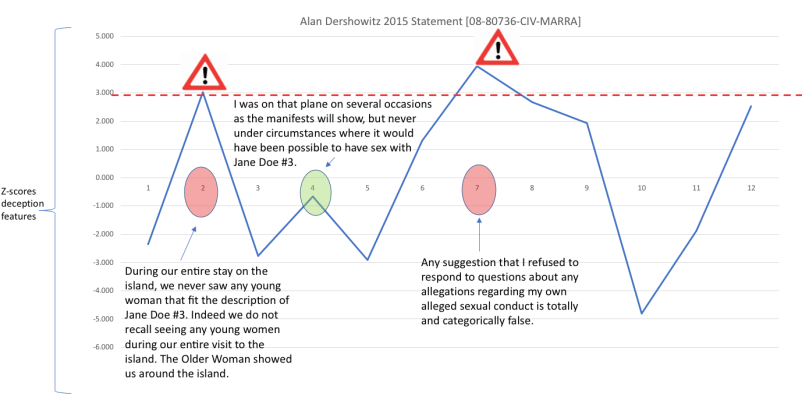
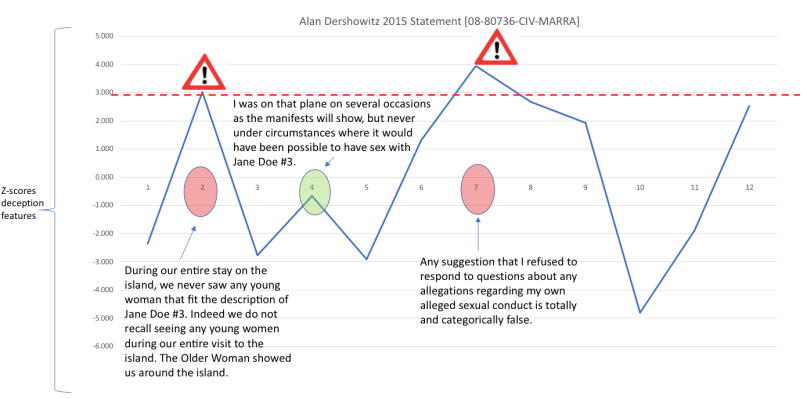
Segment 4: In the filing that Dershowitz is responding to, Giuffre referred to three occasions when Dershowitz allegedly had sex with her. In this segment, Dershowitz responds to the third of these claims:
Third, she has accused me of having sex with her on Jeffrey Epstein’s plane. That is a deliberate lie. I was on that plane on several occasions as the manifests will show, but never under circumstances where it would have been possible to have sex with Jane Doe#3. On a couple of occassions I was on his plane with my wife and daughter. On another occasion, I was on the plane with my nephew and several older people going to see a launch at Cape Kennedy.
Dershowitz admission that he has been on an Epstein plane, considering the notorious reputation of Epstein’s private jet fleet, adds credibility to his denial. After acknowledging that passenger information can be checked (“as the manifests will show”) he gives two examples of trips made and the company he kept, thus inviting external corroboration.
Suspicious segments
Segment 2: In this segment, Dershowitz responds to the first of Giuffre’s claims”
Jane Doe #3 has alleged that she had sex with me on Mr. Epstein’s. Carribean island. That is a deliberate lie. I was on that island only once in my life, for approximately one day. I was with my wife and daughter during the entire day. My wife, daughter and I slept overnight in the same room. We had dinner with Mr. Epstein and a
distinguished professor from the Harvard Business School, his wife, her sister, brother-in-law and their kids, and an Older Woman. During our entire stay on the island, we never saw any young woman that fit the description of Jane Doe #3. Indeed we do not recall seeing any young women during our entire visit to the island. The Older Woman showed us around the island. There is no conceivable possibility that I could have had any sexual encounter with Jane Doe #3 during that period.
Dershowitz distances himself from the situation he describes by introducing a host of characters and then referencing himself as part of a group ‘we’ rather than highlighting his personal non-involvement. It is unclear whether ‘we’ refers to his family alone or the whole entourage i.e. the other Harvard Professor present and his family. The ambiguity around the pronominal referencing is compounded by Dershowitz’s dubious claim to be certain of the cognitive state of everybody present (“Indeed we do not recall seeing…”).
Later in this passage, Dershowitz draws further attention to an “Older Woman” (capitalisation is in the original statement transcript) present at the Epstein dinner, whom he later signals to be not a part of the entourage but rather a host – “The Older Woman showed us around the island”. This “linguistic pointing”, as well as the lack of coherence, suggests that the identity of the “Older Woman” is a ‘point of interest’ and a locus of potential deception.
Segment 7: Just prior to this segment, Dershowitz had been engaging in semantics, objecting to the claim made by Giuffre’s lawyers (Bradley J. Edwards and Paul G. Cassell) that “they tried to depose [him] on these subjects, although he has avoided those deposition requests” because by “using the term ‘these subjects’ in a statement about the sexual abuse charges recently made against me, these lawyers have falsely implied that they sought to depose me on allegations regarding my own conduct.”
Dershowitz then presents himself as the victim:
Any suggestion that I refused to respond to questions about any allegations regarding my own alleged sexual conduct is totally and categorically false. The lawyers know this and yet continue to perpetuate the false impression that I was somehow given an opportunity to respond to these false and salacious charges against me and refused to do so.
The Outliar™ analysis identifies this as potential deception because the victimised language stands in stark contrast to the relatively even tone of the remainder of the statement. However, bearing in mind the nature of the charges and the damage they could cause to one’s reputation (something Giuffre’s lawyers would no doubt have been aware of), it is perhaps not surprising that Dershowitz expressed strong feelings here.
Summary and Postscript
The general credibility of Dershowitz fighting statement is compromised by the mysterious reference to an “Older Woman” (Ghislaine Maxwell?), who was the host on his family trip to Epstein’s island. Investigative question would focus on her identity and might probe how much the visit was ‘stage-managed’ in order to avoid seeing “any young women during our entire visit to the island”.
Alan Dershowitz 2015 statement – full text

Ghislaine Maxwell, a possible candidate for the “Older Woman” mentioned in the statement, in 2003. (Getty)
