

Automated fake news detection is something of a holy grail at the moment in deception research, machine learning and AI in general. Yet, despite all the high profile committees and investigations dedicated to it, fake news is not an isolated problem; it is part of the general epistemic malaise that has caused us to refer to our current era as ‘post-truth’. With this in mind, I have approached the problem of fake news detection building on my work on fake review detection. This is not to trivialise the problem; despite its greater social and political impact, the production of fake news is an equally commercial operation (complete with its own writing factories eg. Macedonia, Kosovo and Maine).
In 2018 I presented a paper on fake book review detection at Stanford University’s Misinformation and Misbehaviour Mining on the Web workshop. One of my key findings was that authentic reviews were significantly more likely to contrast positive and negative aspects of a book, even in 5-star reviews; positive reviewers often hedge their praise and include caveats (see examples 1 and 2 below). Fake reviews were significantly less likely to display such a balance – basically, deceivers were unable to suggest good points and bad points about a book they hadn’t read. Instead, deceptive reviewers would make a single point and then continue on – elaborate – in the same vein, sometimes in a rambling or waffly manner (for example, 3 below).
1. You’re not going to find endless action, shocking plot-twists, or gut-busting comedy. What you will find is a simple beautiful poetic story about life, desire and happiness.
2. Sometimes things happen a bit too conveniently to ring true, sometimes it is predictive, but in the end you won’t care.
3. This story is extremely interesting and thought provoking. It raises many questions and brings about many realizations. As you read it becomes increasingly clear we really are not so different after all. Great read!
Figure 1: Extracts from Amazon book reviews used in Popoola (2018)
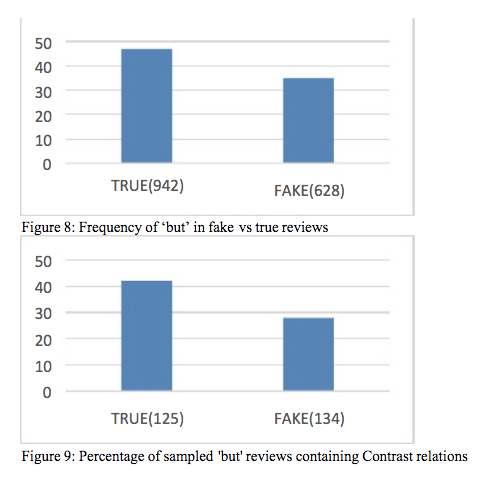
Contrasting is most often (although certainly not always) signalled with ‘but’ – as in example 2 above – so a rough and ready technique for testing whether Contrasting is more common in truth than deception is to compare the frequency of ‘but’ in known real and fake reviews. I followed up my initial findings by analysing 1570 true and fake book reviews and found authentic reviews do use ‘but’ substantially more than fake reviews and that authentic reviews are more likely to use ‘but’ to signal Contrast relations (see Figures 8 and 9 below; full findings, along with data source, can be found in Popoola (2018).)
USE OF ‘BUT’ IN TRUE VS. FAKE REVIEWS
What does this have to do with fake news? Presenting all sides of a case or argument, in the name of objectivity and balance, is a conventional feature of the news story genre because it is fundamental to journalism ethics. Balancing and Contrasting are not the same but linguistically they can be performed with similar language – contrastives. Contrastives include conjunctions such as ‘but’, ‘either’ and ‘or’, conjunctive adverbs such as ‘however’ and prepositions like ‘despite’. This can be contrasted with the use of additives – e.g. ‘and’, ‘also’, ‘in addition – for Elaborating. Contrastives and additives are two of four general linguistic strategies for connecting texts – cohesion devices.
My hypothesis is that there will be variation between the different news sources in the proportion of additives vs. contrastives used – and, just like the book reviews, authentic news sources will use more contrastives. Since additives are the most common way of connecting textual information (‘and’ is the third most common word in English, six times more frequent than ‘but’ – good word frequency list here if you are into that kind of thing), I calculated the relative use of contrastives compared to additives
I piloted this approach on a 1.7million word corpus of political news stories downloaded from 15 news sources in Spring 2017. The 15 sources were a representative mix of legacy and contemporary news media from acrosss the political spectrum: Bipartisan Report; Breitbart; Freedom Daily; The Daily Caller; The Daily Mail; Addicting Info; Alternative Media Syndicate; The Daily Beast; Think Progress; BBC; CBS; CNBC; CNN; The Huffington Post; The New York Times.
I used the following definitions for the cohesion strategies:
- contrastives = ‘but’|’either’|’or’
- additives = ‘and’|’also’|’in addition’.
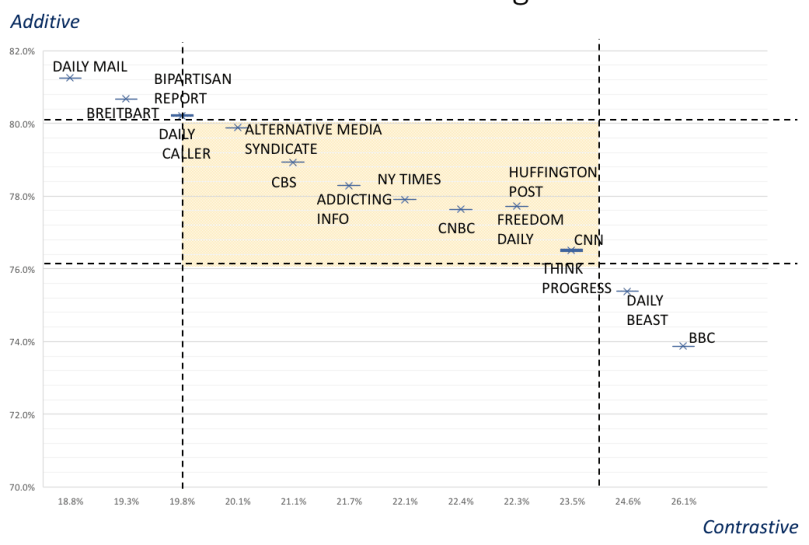
Figure 2 is a scatterplot of each news outlet’s proportion of additive and constrastive relation cues. It shows substantial variation in text cohesion strategies with six news sources lying over one standard deviation from the mean (i.e. outside of the yellow rectangle); additive cohesion is particularly frequent for The Daily Mail, Breitbart, Bipartisan Report and The Daily Caller , while contrastive cohesion is particularly frequent for The Daily Beast and the BBC.
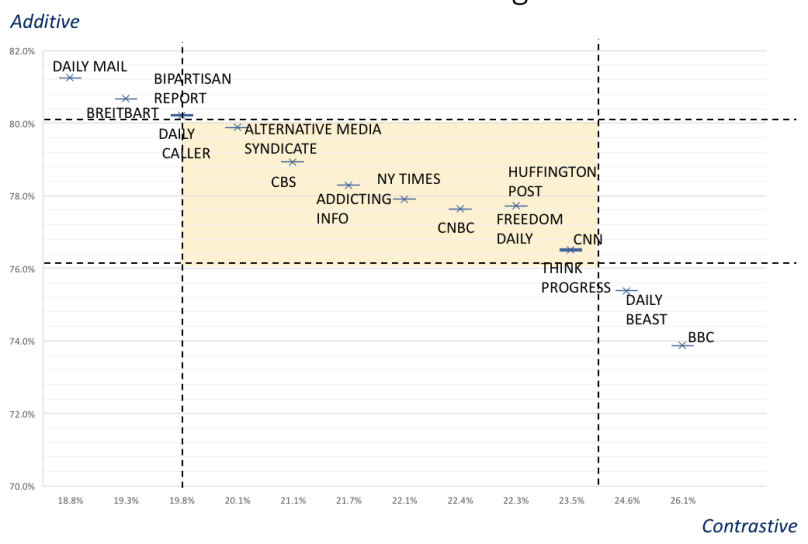
Figure 2: Scatterplot of variation in text cohesion strategies in 15 online news sources. x=Contrastive / [Contrastive+Additive]; y=Additive / [Contrastive+Additive]. Coloured rectangle represents 1 SD from mean.
Example of additive textual cohesion from Breitbart

Full article here: https://www.breitbart.com/politics/2017/03/31/h1b-move-funded-cheap-labor-lobbies/
Example of contrastive textual cohesion from The Daily Beast

Full article here: https://www.thedailybeast.com/nikki-haley-steps-up-in-syria-crisis
So, we can see that the textual cohesion strategies can differentiate articles within the genre. My hypothesis says that the news articles using more additive strategies are more likely to be fake, in this case that The Daily Mail and Breitbart are more likely to produce fake news than the BBC and The Daily Beast. How do we know what is fake? Since we are a looking at the overall source rather than individual articles, we can use a general scoring system. For now, we’ll use the simple ‘failed a factcheck’ test. All the news sources that have ever failed a factcheck are marked in red in Figure 4 below.

Figure 4: Scatterplot of variation in text cohesion strategies in 15 online news sources. News sources with failed factchecks marked red (source: mediabiasfactcheck.com)
As can be seen, 9 of the 15 news sources have failed a factcheck recently; factchecking by itself is not the most sensitive discriminator. However, 6 of the 15 news sources tend towards additive cohesion strategies and all 4 of the highest additives have failed factchecks whilst neither of the prototypical contrastive texts are ‘fake by this definition.
So, it would seem that just like with fake book reviews, there is a tendency for fake news to lack shades of contrast. Perhaps deceivers are less likely to contrast their lies with the truth because it dilutes their deception. As you read, I’ve been adding more news sources to the analysis and refining the cohesion strategy specifications. Stay tuned!
