
So here’s the thing. You can tell somebody is lying – or more correctly, deceiving – by the words they use. I’m not talking about gesture or disguise or other types of non-verbal deception. I mean when there are words and text – either written or spoken – those words will reveal deception if you know what to look for.
“Listen, nobody believes in doping controls more than me.” — Lance Armstrong
Does that mean it’s possible to detect deception by reading a text or transcript or listening to someone speak? Not exactly. Factors such as human truth bias and our reliance on heuristics to process information mean that judgement derived from our senses is not entirely reliable (although it can be improved by education and training).
Deception detection is possible by processing a text. Now, unless you are some kind of artificial intelligence, you will rely on an automated tool for computational and statistical analysis. Non-verbal deceptions such as credit card or other financial fraud are already detected using statistical algorithms and other data mining techniques. Advances in linguistics mean that texts can also be processed as data and then classified and grouped together – all without being read or heard.
There are different features of language that can be analysed. Words, word sequences, types of words, grammar, syntax and so on. These features can be analysed individually or as groups that represent underlying concepts (e.g. ‘certainty’ or ‘complexity’). You can analyse known true and deceptive texts for these language features, compare the frequencies and distributions, and find linguistic tendencies that correlate with deception and truth. But what are these linguistic features?
There are many sets of linguistic features that have been used for deception detection (see Hausch et al’s 2015 meta-analysis for a comprehensive list of experiments and linguistic features used). The features that are most effective are the ones that enable the linguistic act of deception.
Take the following:
– “ Car.”
By itself, this single common noun cannot be a lie. If I said ‘car’ and pointed to a bicycle or a phone then that could be a lie. There are linguistic different resources for ‘pointing’:
– “That is a car.”
– “I have a car”
– “My car”
In fancy linguistic terminology, ‘pointing’ is known as referential indexicality. Other types of ‘pointing’ can be to a particular place, period of time, event, assumption, thought and so on – even to the text itself. Drawing on the linguistic theory and influence of the Prague School, I use a set of these linguistic features to analyse texts for ‘textual hotspots’ – a linguistic equivalent of the non-verbal hotspots such as micro-expression, gesture and voice identified by the psychologist Dr Paul Ekman (on whom the TV show, ‘Lie To Me’ is based).
I have developed a tool for identifying these linguistic hotspots using anomaly detection techniques adapted from banking fraud. Research has shown that these linguistic deception features cluster together when deceptive language is being used. Ergo, anomalous clusters of linguistic features that point to deception are areas of potential deception. Not to steal Dr Ekman’s thunder, I am calling these anomalous textual hotspots ‘outliars’.
I’ve tested this hypothesis on a number of known deceptions and the results, which are promising, were presented at the Decepticon 2017 conference held at Stanford University. I chose statements made by sportspersons about the use of performance-enhancing drugs and doping because these are high-stakes deceptions and so more likely to leave linguistic traces.

One of the most famous examples of doping deception is Lance Armstrong. How did Lance Armstrong successfully deceive so many millions for so long? Bullying, good lawyers and a fairytale narrative of cancer recovery and global charity certainly played their part. But the key to Armstrong maintaining this deception – through various testimony, interviews, biographies – was his sustained verbal performance.
One classic example is Armstrong’s 2005 interview with Bob Ley on the ESPN show ‘Outside the Lines’.’Outside the Lines’ is an investigative ESPN TV series that takes a critical look at American sports issues. This interview was conducted by the usual anchorman, Bob Ley. Armstrong was a year into his first retirement, after winning his 7th Tour de France in 2005 and had just been cleared of doping allegations after a lengthy trial. The show is renowned for its tough questioning and investigative slant, and Bob Ley did not hold back. Below is a transcript of the interview.
Figure 1 shows my ‘Outliar’ analysis of the responses. The analysis picks out two linguistic hotspots of potential deception – sections 5 and 12. These are highlighted in the transcript but I’m going to lay them out here for analysis.
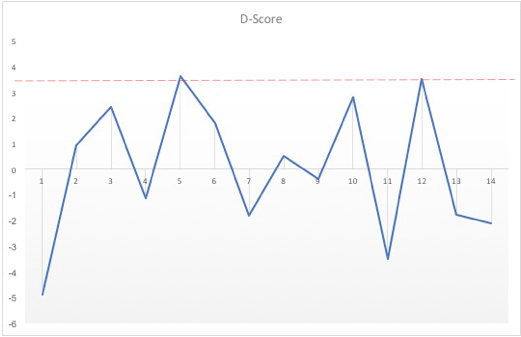
Figure 1: Outliar analysis of Lance Armstrong’s interview responses. Armstrong’s interview responses are represented as a time series on the x-axis (c.30 second chunks). The y-axis measures the relative frequency of linguistic deception features; text segments scoring over 3.5 are recorded as anomalous (the Iglewicz-Hoaglin method).
Segment 5 contains the following extract. Bob Ley had asked whether it was true Armstrong had made a phone call to Dr Prentice Steffen threatening “to spend a lot of money to make your life miserable” if Steffen did not retract comments accusing Armstrong of doping [transcript lines 46-50].
ARMSTRONG: Not true. Steven, er Prentice Steffen I think was his name, was not part of the team when I was there, I hardly know him. The only interaction I ever had with him I think was when he was a team doctor with the Mercury cycling team and I helped one of their young riders I think get care for testicular cancer. That’s the first and only interaction I ever had with him.
In this outlier extract, Armstrong denies the accusation by distancing himself from Dr Prentice Steffen (Steven, Stefan, what was his name again?). Instead he foregrounds his charity work for an anonymous sick rider. The underlined sentence introduces three new referents – a young rider, Mercury and cancer. Such a topic shift and introduction of third party issues is a pragmatic technique for diverting attention. The cluster of pronouns picked out by the analysis – ‘he’, ‘their’, ‘I’– facilitate the diversion and leave the final ‘him’ ambiguous (technically this ‘him’ should refer to the nearest qualifying noun i.e. ‘one of their young riders’).
In contrast, the following extract from segment 8 is representative of Armstrong’s ‘baseline reading”. Bob Ley had asked whether it was true Armstrong had made a phone call to Greg Lemond, threatening to smear him: “I can produce 10 people that say you took EPO”:
With regards to Greg Lemond I have to say as a young guy, I did idolize him in 1989, I think we all remember that incredible story coming back after getting shot and winning the tour by 8 seconds, the smallest margin ever. I mean he was a guy that quite literally put all of us into cycling, because he was appealing to us at a young age. But, er, for a past champion and a great champion, one of the greatest athletes of all time, to be so involved in a case, I mean I ask you Bob, I ask the viewers, why would you be so involved?
In answering this, Armstrong appears to show rare humility; he acknowledges his own inspiration and even someone else’s achievements. However, a closer reading reveals a mocking tone in which Armstrong draws attention to the narrowness of LeMond’s victory – “winning the tour by 8 seconds, the smallest margin ever”. The transcript shows that taunting accusers is Armstrong’s baseline linguistic behaviour in this interview, which is why the reticent language used when discussing Dr Prentice Steffen in segment 5 stands out as deceptive.
The analysis also flags the following segment 12 as a linguistic hotspot of potential deception. Here Ley has asked Armstrong about his attempts to shut down the World Anti-Doping Agency (WADA) investigation that was shining a light on doping in cycling and Armstrong at that time.
Now there’s two people involved in this process. There’s the athletes and there’s the people who police the athletes. And both of them have to be ethical. Listen, nobody believes in doping controls more than me. I’ve submitted to all of them, whether in competition or out of competition. Now listen, I’m not saying my best defence is I’ve never tested positive. All I’m saying is that the last few years when you were supposed to tell the investigators and the drug testers everywhere you were everyday of the year, I did it.
Here, rather than taunting accusers, Armstrong again points the linguistic finger. He insinuates that the drug testing process and its ubiquitous participants (‘people’, ‘investigators’, ‘testers’) may not be ethical and he portrays himself as a willing (and perhaps slightly persecuted) subject to the testing regime. However, with the assertion “nobody believes in doping controls more than me”, Armstrong leaks the fact that he has been expert at manipulating the drug testing system. He immediately realises this ‘slip’ and moves to deny its implicature that his “best defense is I’ve never tested positive”. The final ‘it’ is ambiguous and difficult to resolve – a deception strategy we also saw in the above segment 5.
There are more examples like this in my Decepticon 2017 Stanford presentation (including an interesting connection between doping and asthma!) so take a look at that if you are interested in more detail on the method (or write to me). But the real value of this method, I think, is as an investigative linguistic tool which can identify ‘points of interest’ and thus aid forensic and journalistic investigations. So future blog posts will probe the public statements and testimony related to the key events, scandals and crimes of this post-truth era.

[…] facilitate deception because they are malleable to context and flexible to interpretation. My first blog post showed that deceptive communication contains ‘outliars’, portions of texts with an […]
LikeLike
[…] November 1, 2020November 1, 2020 Olu PopoolaLeave a comment Outliar(TM) analysis of President Trump talk in October 22 Presidential Debate. x=text segments (50 words); y=relative frequency of linguistic deception features (Z-score). More details on methodology here. […]
LikeLike